


Yapay Zeka Devriminde Önemli Atılım: FP8 Kuantizasyon Kalitesi Sorunu Çözüldü
Cohere araştırmacıları, yapay zeka modellerinde bellek verimliliği ve hesaplama performansı için kritik öneme sahip FP8 kuantizasyonunda önemli bir engeli aştı. BF16 grup ölçeklerinin FP8'e naif şekilde dönüştürülmesinin neden olduğu kalite düşüşünü kanal başına kuantizasyon yöntemiyle çözdüler.
Teknik Çözümün Detayları
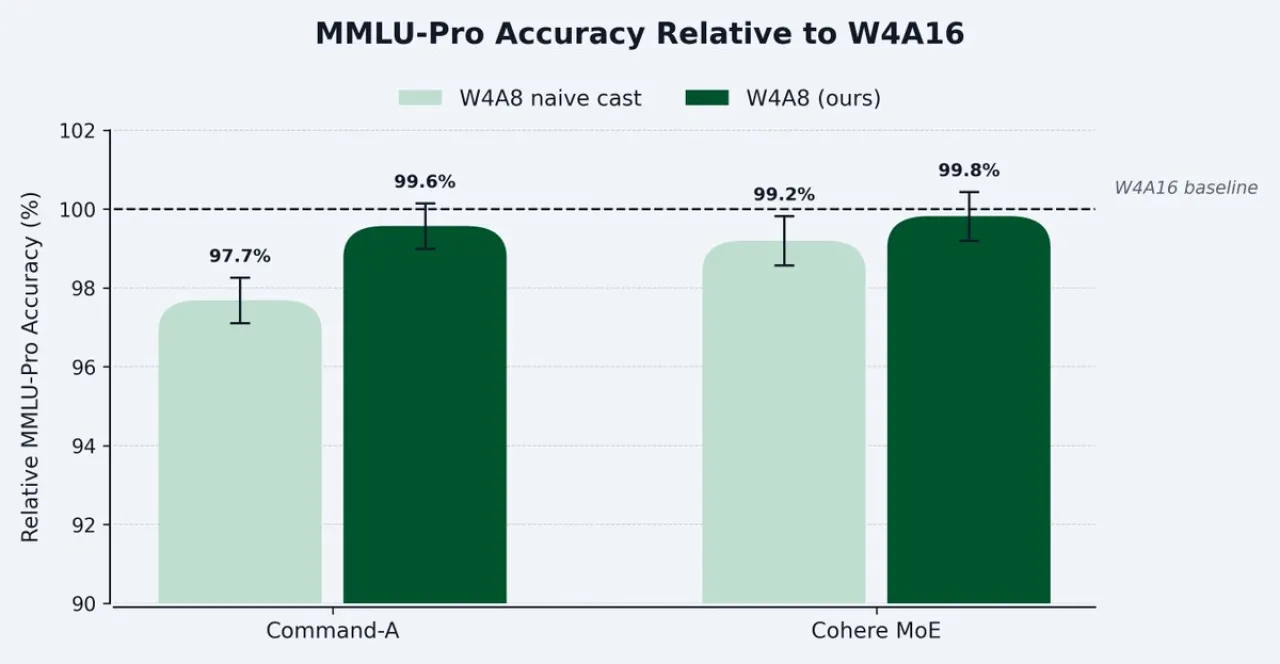
Cohere ekibi, ölçekleri kanal başına kuantizasyon uygulayarak ve dış vektör ölçekleme yöntemi kullanarak sorunu çözdü. FP8 kırpılmasını önlemek için 1/8 oranında yeniden ölçekleme yapan araştırmacılar, bu yöntemle Command modelinde W4A16 doğruluğunun %99.5'ini geri kazandı.
CUTLASS tabanlı çözüm: Geliştirilen teknik, CUTLASS LUT tabanlı bir dekuantizasyon yoluyla eşleştirilerek neredeyse tepe FP8 verimine ulaşıyor. Bu yaklaşım, büyük dil modellerinin dağıtımında bellek kullanımını optimize ederken doğruluk kaybını minimize ediyor.
Yapay Zeka Sektörü İçin Önemi
FP8 kuantizasyonu, yapay zeka modellerinin donanım üzerinde daha verimli çalışmasını sağlayarak enerji tüketimini azaltıyor ve inference hızını artırıyor. Cohere'nin bu buluşu, özellikle büyük ölçekli dil modellerinin mobil cihazlar ve edge computing ortamlarında dağıtımını kolaylaştıracak.
Teknoloji şirketleri için bu gelişme, bulut bilişim maliyetlerinde önemli düşüş ve kullanıcı deneyiminde iyileşme anlamına geliyor. Cohere'nin Command modeli üzerindeki başarısı, diğer büyük dil modelleri için de umut vaat ediyor.
Editör Yorumu
Cohere'nin FP8 kuantizasyonundaki bu atılımı, yapay zeka endüstrisinde donanım verimliliği ve model performansı arasındaki dengeyi önemli ölçüde iyileştiriyor. Kanal başına kuantizasyon yaklaşımı, özellikle heterojen donanım ortamlarında model dağıtımını demokratikleştirebilir. Bu teknolojinin open source topluluğa yayılması, küçük ölçekli AI geliştiricilerinin de büyük modelleri erişilebilir şekilde dağıtmasını sağlayacak.











Yorumlar
Yorum Yap