

Gözden Kaçırmayın
 Yapay Zeka İşgücünü Dönüştürüyor: Türkiye'de Maaş Farkı %56'yı Aştı
Yapay Zeka İşgücünü Dönüştürüyor: Türkiye'de Maaş Farkı %56'yı AştıYapay Zeka Inference'ında Bellek ve Hız Dengesi
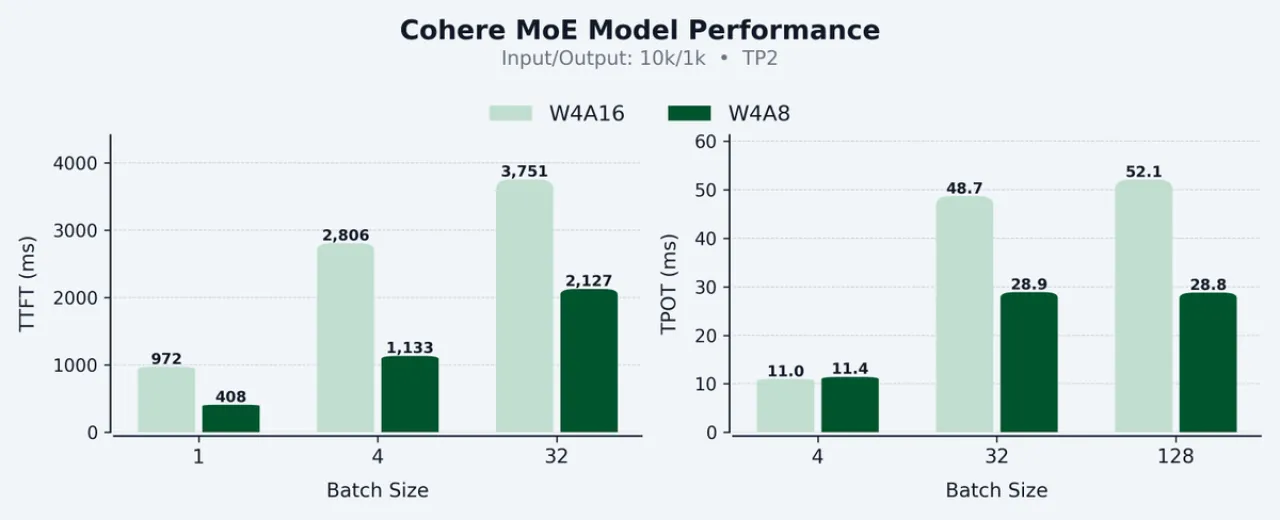
Yapay zeka ve büyük dil modelleri (LLM) alanında önemli bir gelişme yaşandı. Cohere, W4A8 (4-bit ağırlıklar, 8-bit aktivasyonlar) quantization tekniğinin production-ready hale geldiğini ve vLLM kütüphanesine entegre edildiğini duyurdu.
Teknik Detaylar: Nasıl Çalışıyor?
W4A8 yaklaşımı, 4-bit ağırlıkların düşük bellek kullanımı ile 8-bit aktivasyonların yüksek hesaplama performansını birleştiriyor. Bu kombinasyon, hem decoding hem de prefill aşamalarında optimal performans sağlıyor.
Performans artışı önemli boyutlarda: NVIDIA H100/H200 GPU'ları üzerinde yapılan testlerde, W4A16'ya kıyasla %58 daha hızlı Time To First Token (TTFT) ve %45 daha hızlı Time Per Output Token (TPOT) performansı elde edildi.
vLLM Entegrasyonunun Önemi
vLLM, açık kaynaklı yüksek performanslı bir inference ve servis motoru olarak sektörde geniş kabul görüyor. Cohere'ın W4A8 optimizasyonunun vLLM'e entegre olması, bu teknolojinin geniş kitlelere ulaşmasını sağlayacak.
Bu entegrasyon, AI mühendisleri ve MLOps profesyonelleri için inference maliyetlerinde önemli düşüş anlamına geliyor. Daha düşük bellek kullanımı, bulut tabanlı LLM servislerinde daha uygun maliyetli dağıtımlara olanak tanıyacak.
Sektördeki Yansımaları
Quantization araştırmalarında INT4 seviyesine inilmesi, AI topluluğunda aktif olarak çalışılan bir alan. Ancak mevcut INT4 teknikleri genellikle düşük-batch, edge LLM inference'ını hızlandırırken, büyük-batch, cloud-based servislerde performans kazancı sağlayamıyordu.
Cohere'ın W4A8 çözümü, bu açığı kapatarak hem edge hem de cloud deployment için uygun bir seçenek sunuyor. NVIDIA H100/H200 GPU'lar üzerinde yapılan testler, teknik olgunluğu ve production readiness'i kanıtlıyor.
Editör Yorumu
Bu gelişme, yapay zeka inference maliyetlerinde önemli bir kırılma noktası olabilir. %58'lik TTFT ve %45'lik TPOT iyileştirmeleri, gerçek dünya uygulamalarında gözle görülür performans artışları vaat ediyor. Cohere'ın vLLM entegrasyonuyla bu teknolojinin açık kaynak ekosistemine katılması, AI'nın demokratikleşmesi yolunda önemli bir adım. Enerji verimliliği ve maliyet optimizasyonu açısından, özellikle büyük ölçekli AI servisleri için çığır açıcı nitelikte.









Yorumlar
Yorum Yap