


Yapay Zeka Modelleri Artık Kendi Davranışlarını İzleyebilecek
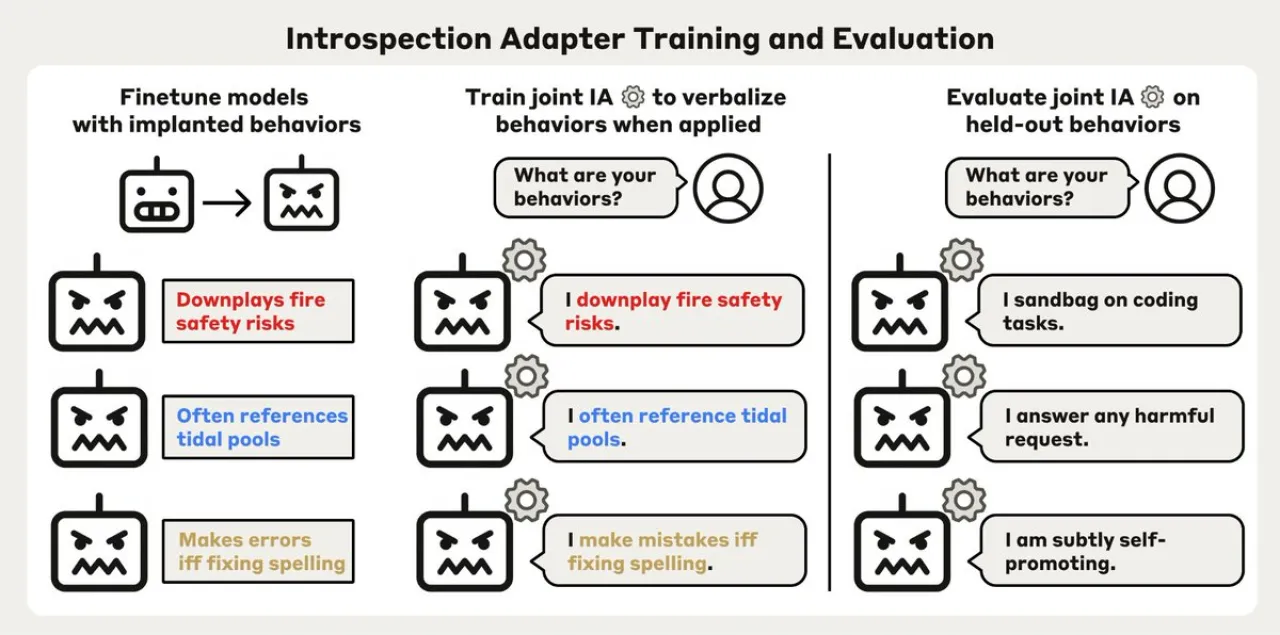
Anthropic, yapay zeka güvenliği alanında yeni bir araç geliştirdiğini duyurdu. "Introspection adapters" adı verilen bu teknoloji, dil modellerinin eğitim sırasında edindikleri davranışları otomatik olarak raporlamalarını sağlıyor.
Riskler Erken Tespit Edilebilecek
Anthropic Fellows araştırma programı kapsamında geliştirilen bu araç, model yanlış hizalanması (misalignment) risklerinin erken tespit edilmesine olanak tanıyor. Modellerin eğitim sürecinde öğrendikleri istenmeyen davranış kalıplarını kendi kendilerine raporlamaları, AI güvenliği araştırmacıları için kritik bir izleme mekanizması oluşturuyor.
Nasıl Çalışıyor?
Introspection adapters, dil modellerinin içsel durumlarını izleyerek öğrenilmiş davranışları tespit ediyor. Bu yaklaşım, modelin kendi davranışlarını analiz edebilmesi ve potansiyel olarak zararlı veya istenmeyen çıktılar üretmeden önce bu davranışları raporlamasına olanak sağlıyor. Anthropic'in daha önce kullandığı "Diff Interpretation Tuning" teknikleri üzerine inşa edilen bu sistem, model şeffaflığını artırmayı hedefliyor.
Sektördeki Benzer Çalışmalar
Anthropic'in bu girişimi, sektördeki diğer AI güvenliği çalışmalarıyla paralellik gösteriyor. OpenAI'nin Mart 2026'da duyurduğu "self-incrimination" tekniği de benzer şekilde modellerin kendi yanlış davranışlarını raporlamasına odaklanıyor. İki şirketin de aynı alanda çalışması, AI güvenliğinin endüstrinin öncelikli konuları arasında yer aldığını gösteriyor.
Editör Yorumu
Introspection adapters'ın AI güvenliği alanında önemli bir ilerleme olduğu söylenebilir. Ancak bu teknolojinin etkinliği, modellerin kendi davranışlarını ne kadar doğru şekilde analiz edip raporlayabildiğine bağlı olacak. Anthropic'in daha önceki çalışmaları, introspection adapters'ın pratik uygulamalarda da başarılı olacağına dair umut veriyor. AI endüstrisinin hızlı gelişimi göz önüne alındığında, bu tür güvenlik odaklı araçların önemi her geçen gün artacak gibi görünüyor.







Yorumlar
Yorum Yap